Sistemi Operativi: Vmbo
Continua la serie di progetti sviluppati a scopi didattici per l’Università di Urbino “Carlo Bo”.
Specifica del problema
Scrivere un programma multithread che consenta di valutare le performance, in termini di numero di page fault, di algoritmi di rimpiazzamento delle pagine per la gestione della memoria virtuale.
Il programma dovrà essere costituito da un’entità principale che operi come una Memory Management Unit (MMU), un numero arbitrario (n) di thread, ove ogni thread emuli un singolo processo (PROCESSO) e, infine, da un’entità che emuli un dispositivo di I/O (DISPOSITIVO I/O).
Il programma dovrà simulare una sessione di lavoro, nella quale sono presenti n processi che possono accedere alla memoria e generare richieste di I/O. I processi dovranno generare indirizzi di memoria casuali. Infine, il programma terminerà una volta raggiunto il numero prestabilito di accessi in memoria totali.
MMU
L’entità MMU sarà la base del sistema ed utilizzerà l’algoritmo di rimpiazzamento delle pagine oggetto di test. Essa dovrà essere istanziata dal thread principale (main) e sarà gestita come oggetto condiviso tra i diversi thread dei PROCESSI. In particolare essa definirà la dimensione dello spazio di indirizzamento virtuale, la dimensione della memoria fisica disponibile e la dimensione della pagina.
La MMU dovrà, inoltre, contenere una lista di tabelle della pagine ciascuna relativa ad un PROCESSO. La definizione della specifica delle tabelle delle pagine sarà lasciata allo studente, e naturalmente dipenderà dal particolare algoritmo di rimpiazza mento implementato.
I PROCESSI dovranno generare indirizzi verso la MMU invocandone un metodo pubblico.
L’accesso a tale metodo dovrà garantire la mutua esclusione (un solo PROCESSO alla volta potrà invocare il suddetto metodo. La mutua esclusione dovrà essere ottenuta utilizzando le primitive di sincronizzazione messe a disposizione dal linguaggio di programmazione eccezion fatta per il costrutto monitor (per chiarezza, ad esempio, in java non sarà possibile utilizzare il costrutto synchronized).
Il metodo in questione processerà la richiesta andando ad interrogare l’opportuna tabella delle pagine. Nel caso in cui, l’indirizzo generato sia relativo ad una pagina già mappata in memoria la MMU si limiterà ad incrementare un contatore statistico di page hit. D’altra parte, nel caso in cui l’indirizzo generato dal PROCESSO faccia riferimento ad un indirizzo contenuto in una pagina non mappata in memoria la MMU dovrà eseguire i seguenti passi:
- incrementare un contatore di page fault
- selezionare una pagina mappata da rimuovere (vittima) secondo la politica dell’algoritmo oggetto di test
- aggiornare le opportune tabelle delle pagine
- indicare come non valida la pagina che è appena stata rimossa
- inserire una nuova entry nella tabella delle pagine del PROCESSO che ha generato il page fault (la pagina è stata appena caricata).
PROCESSO
L’entità PROCESSO dovrà emulare un processo in esecuzione su di un sistema multi programmato. Ogni processo dovrà essere emulato attraverso l’utilizzo di un singolo thread. Lo scheduling dei thread sarà delegato alle librerie messe a disposizione dal linguaggio di programmazione (configurazione default).
Il comportamento di ogni PROCESSO può essere descritto da una macchina a stati finiti comprendente due soli stati mutuamente esclusivi:
- Richiesta indirizzo di memoria (invocazione del metodo pubblico della MMU);
- Richiesta operazione di I/O (invocazione del metodo pubblico del DISPOSITIVO di I/O).
Le transizioni tra i due stati dovranno essere gestire in maniera probabilistica. In particolare, dovrà essere definita una probabilità p (input fornito al momento del lancio dell’applicazione) di generare indirizzi di memoria (“entrare nello stato a dato che ci si trovava nello stato b” = “rimanere nello stato a”) e una probabilità q = 1-p di generare richieste di I/O (“entrare nello stato b dato che ci si trovava nello stato a” = “rimanere nello stato b”).
I PROCESSI dovranno prevedere la possibilità di essere inizializzati con diversi valori di probabilità p.
DISPOSITIVO di I/O
L’entità DISPOSITIVO di I/O dovrà essere gestita come un ulteriore thread. Questa avrà un metodo pubblico attraverso il quale i PROCESSI potranno effettuare una richiesta di I/O.
Le richieste di I/O dovranno essere gestite con un coda di tipo FIFO. Le richieste saranno, ovviamente, bloccanti, mettendo il PROCESSO chiamante in uno stato di attesa fino al soddisfacimento della richiesta.
Il DISPOSITIVO di I/O determinerà il tempo di servizio di ciascuna richiesta in modo casuale estraendo a caso un valore intero, espresso in millisecondi, compreso fra Tmin e Tmax (parametri di inizializzazione del DISPOSITIVO di I/O).
Dati di INPUT
Il programma dovrà ricevere in input i seguenti parametri di inizializzazione:
- Numero di PROCESSI
- Probabilità p di generare accessi in memoria (una p per ogni PROCESSO; la probabilità di accedere al dispositivo di I/O sarà pari a 1-p);
- Tempi di servizio minimi e massimi del DISPOSITIVO di I/O (Tmin e Tmax);
- Numero totale di accessi in memoria raggiunto il quale il programma dovrà terminare.
Dati di OUTPUT
Al termine della simulazione il programma dovrà stampare a video la percentuale di page fault totale (relativa a tutti i processi), la percentuale di page fault relativa a ciascun PROCESSO, il tempo medio di servizio del DISPOSITIVO di I/O ed il tempo medio di attesa per una richiesta di I/O relativo a ciascun PROCESSO.
Ciascun PROCESSO dovrà scrivere in un proprio file di log la successione di indirizzi generata e le chiamate al dispositivo di I/O.
Analisi del problema
Il problema richiede di realizzare un simulatore elementare di memoria virtuale, utile all’analisi del comportamento e relative prestazioni di un algoritmo di rimpiazzo delle pagine. Il sistema realizzato simulerà un ambiente di lavoro multi programmato, nel quale operano più processi contemporaneamente.
Un’analisi iniziale ci suggerisce che questo problema sia di tipo decidibile, ovvero presuppone l’esistenza di un algoritmo che lo risolva in tempo finito e per una qualunque istanza di dati, espressa in termini di numero di processi contemporanei, dimensione della pagina e così via.
Come da specifica, il simulatore non avrà bisogno di alcun dato di ingresso per funzionare. Un insieme esteso di parametri da riga di comando permetterà di alterare alcuni aspetti e funzionalità del simulatore.
L’output del programma sarà costituito da alcuni dati statistici, prodotti a seguito del numero prestabilito di accessi alla memoria.
Progettazione dell’algoritmo
La scelta della struttura dati e del relativo algoritmo tiene conto dei parametri dettati dalla specifica del problema: l’attenzione sarà dunque focalizzata sulla politica di rimpiazzo delle pagine, sulle strutture dati necessarie ed sullo scenario che tali scelte determinano; l’analisi non terrà quindi in considerazione l’impatto che il paging nella memoria secondaria possa avere sull’efficienza complessiva del sistema, né dei tempi d’accesso alla memoria o di caricamento di una pagina.
Si è scelto di articolare il programma in tre fasi distinte:
- analisi dei parametri forniti su riga di comando: di particolare rilievo, la possibilità di modificare alcuni parametri di funzionamento del simulatore;
- inizializzazione delle strutture dati e successiva esecuzione dei singoli thread;
- attesa del completamento dei thread, relativa deallocazione delle strutture dati e successiva stampa delle statistiche.
Descrizione del simulatore
Un sistema dotato del meccanismo di memoria virtuale consente ad un processo di allocare una quantità di memoria superiore a quella effettivamente disponibile. La tecnica si basa sull’utilizzo di altri tipi di memoria, detta secondaria, che entrano in gioco quando la memoria fisica risulta piena. Il meccanismo di memoria virtuale implementato per il simulatore è quello della paginazione.
La paginazione prevede la suddivisione della memoria fisica in frame, tutti della stessa dimensione; analogamente, anche la memoria allocata da un processo viene diviso in pagine, la cui dimensione è pari a quella di un frame di memoria fisica: tale suddivisione avviene ad opera della mmu, in modo totalmente trasparente al processo utente.
Al pari di un sistema operativo, il simulatore terrà aggiornata una tabella dei processi attivi: ogni voce nella tabella è rappresentativa di un processo e delle pagine virtuali allocate.
Per semplicità, si suppone che la tabella dei processi e la relativa page table siano sempre residenti in memoria, ovvero che queste non vengano mai paginate a loro volta.
Perché un processo possa accedere ad un’informazione contenuta in una determinata pagina virtuale, è necessario che quest’ultima sia presente nella memoria fisica ovvero, nello specifico, che sia associata ad un frame. Quando la lista dei frame disponibili non è esaurita, sarà sufficiente associare la pagina richiesta ad un frame disponibile; nel caso contrario, si dovrà applicare una politica di rimpiazzo delle pagine, volta a selezionare una pagina tra quelle presenti in memoria, spostarla nella memoria secondaria e associare il frame appena liberato alla pagina richiesta.
L’algoritmo di rimpiazzo delle pagine scelto è l’enhanced second chance, noto anche come algoritmo dell’orologio: tale soluzione nasce come una naturale evoluzione della tecnica FIFO, superando il problema di rimuovere le pagine usate più di frequente.
La realizzazione di tale algoritmo impone che ogni pagina contenuta nella page table del processo, oltre le comuni informazioni, debba contenere due ulteriori bit:
- bit reference ( R): verrà posto al valore uno (1) quando si accederà alla pagina in questione, sia in scrittura che lettura: tale informazione permetterà di sapere se ad una pagina presente in memoria si sia acceduto di recente o meno;
- bit dirty (D): verrà posto ad uno (1) quando si accederà alla pagina in scrittura: quando una pagina dovrà essere rimossa dalla memoria, il valore uno di questo bit suggerirà al sistema operativo di fare una copia della pagina nella memoria secondaria, prima della rimozione dalla memoria principale.
La ricerca della pagina virtuale da rimuovere dovrà tenere conto delle quattro possibili combinazioni ottenute con questi due bit:
| r | d | descrizione | azione |
|---|---|---|---|
| 0 | 0 | *la pagina non è stata usata di recente e non è stata modificata* | *rimpiazza la pagina* |
| 0 | 1 | *la pagina non è stata usata di recente ma è stata modificata* | *effettua un **write **back della pagina e imposta ad zero il bit D* |
| 1 | 0 | *la pagina è stata usata di recente ma non è stata modificata* | *imposta a zero il bit R* |
| 1 | 1 | *la pagina è stata usata di recente ed è stata modificata* | *imposta a zero il bit R ed effettua il write back della pagina* |
La ricerca della pagina migliore non solo si traduce nella selezione della pagina non usata di recente, ma anche di quella che non sia stata modificata. In questo modo, le pagine utilizzate più di frequente hanno alta probabilità di rimanere nella memoria principale, a discapito delle pagine a cui si è acceduto meno frequentemente.
Quando una pagina presente in memoria risulta sporca, si dovranno quindi effettuare due operazioni di I/O: il primo accesso alla memoria secondaria sarà necessario per effettuare il page out, ovvero copiare la pagina sporca sul disco, mentre una seconda operazione di lettura sarà necessaria per il page in della pagina che ha generato il fault. In questo scenario, l’algoritmo scelto, analizzando periodicamente le pagine che risultano sporche e provvedendo ad un preventivo write back nella memoria secondaria, migliora sensibilmente le prestazioni complessive, nonché il tempo medio d’accesso alla memoria.
Tale algoritmo, tuttavia, ha lo svantaggio di partizionare l’insieme delle pagine in due classi: quelle usate di recente e quelle usate con minor frequenza; quando termina la ricerca per il rimpiazzo, non è detto che la pagina identificata sia la più vecchia in assoluto, ma semplicemente una delle pagine meno utilizzate di recente.
Il caso migliore si verifica quando il primo frame analizzato ha i bit R e D posti a zero: la ricerca termina immediatamente e non sarà nemmeno necessaria un’operazione di I/O volta a fare una copia della pagina nella memoria secondaria.
Come da requisito, i processi effettuano soltanto l’operazione di lettura della memoria: è tuttavia possibile alterare questo comportamento specificando il parametro “–w” da riga di comando, per ottenere una simulazione che prevede l’uso del bit dirty.
Il caso peggiore dell’enhanced second chance si verifica quando tutte le pagine residenti in memoria sono sia referenziate che modificate: in questo caso, l’MMU dovrà necessariamente scorrere interamente la lista delle pagine presenti, ottenendo la medesima complessità dell’algoritmo FIFO.
Da tali considerazioni, è facilmente comprensibile che la complessità dell’algoritmo sia O(n), ovvero lineare e proporzionale al numero di frame in cui è stata suddivisa la memoria.
Non meno importante è sottolineare che, essendo un’evoluzione della tecnica FIFO, tale approccio soffre dell’anomalia di Belady (si veda a tal proposito il test 7).
Nei sistemi moderni, alcune funzionalità utili all’implementazione di tale algoritmo vengono implementate direttamente dall’hardware, quale, ad esempio, l’impostazione ad uno del bit reference e dirty ogni qualvolta una pagina venga referenziata o modificata.
Un algoritmo di rimpiazzo può essere di tipo locale o globale: il simulatore proposto effettua una ricerca globale, ovvero quando avviene un page fault, l’MMU cercherà la pagina candidata alla rimozione dalla memoria tra le pagine di tutti i processi attivi e non limitandosi alle pagine allocate del processo corrente. Sebbene una ricerca locale prevenga influenze da parte degli altri processi in termini di page fault, un algoritmo globale risulta complessivamente più efficiente nonché più semplice da implementare.
La modalità di generazione degli indirizzi, ad opera dei processi utente, è in linea con il principio di località, secondo cui se la CPU sta accedendo ad uno specifico dato (o istruzione), con molta probabilità i prossimi dati (o istruzioni) saranno ubicati nelle vicinanze di quella in corso: valutare tale principio ed i suoi impatti è di fondamentale importanza per il funzionamento e le prestazioni della memoria virtuale gerarchica dei moderni sistemi.
È stato, in ultimo, scelto un approccio di tipo pure demand paging, il quale prevede di non assegnare alcun frame al processo fintanto che la pagina non venga referenziata.
I vantaggi di tale tecnica sono immediatamente percepibili:
- le pagine inutilizzate non vengono mai caricate in memoria, aumentando la quantità di memoria disponibile ad altri processi;
- all’avvio di un programma, viene ridotta la latenza necessaria a caricare le pagine in memoria;
- minor carico di I/O dovuto ad un minor numero di pagine da caricare.
In presenza di un sistema con poca memoria fisica disponibile, il demand paging assicura un grado più elevato di concorrenza di processi.
Per semplicità, si è assunto che le pagine contenenti le istruzioni del processo siano sempre residenti in memoria: soltanto le pagine contenenti dati verranno gestite dalla MMU e dalla suddetta politica di rimpiazzo.
Il sistema emulato farà uso di indirizzi a 20 bit: da un punto di vista fisico, un simile spazio di indirizzamento consente di gestire una memoria fisica composta, al massimo, da 1,048,576 byte: il simulatore sarà appunto dotato di questo quantitativo, sebbene sia possibile alterare tale aspetto con l’opportuno parametro da riga di comando (-R).
Anche i processi utente utilizzano un indirizzamento a 20 bit; lo spazio d’indirizzamento virtuale sarà ovviamente superiore a quello fisico in quanto si dovrà considerare anche la memoria secondaria. Sono dunque possibili due scenari che, in assenza del meccanismo di memoria virtuale, non potrebbero sussistere:
- più processi contemporanei, ognuno dei quali alloca il massimo della memoria fisica: la somma di tutti gli spazi d’indirizzamento risulta maggiore della memoria fisica;
- un sistema dotato di una quantità ridotta di memoria fisica ma che consente ugualmente ad un processo di allocare 1Mb di memoria virtuale.
Un indirizzo virtuale a 20 bit generato da un processo sarà suddiviso, in modo del tutto trasparente, in due parti distinte: i otto bit più significativi (da 19° al 12°) verranno usati come indice per consultare la page table del processo, mentre i restanti dodici bit rappresenteranno l’offset da sommare all’indirizzo di partenza del frame associato.
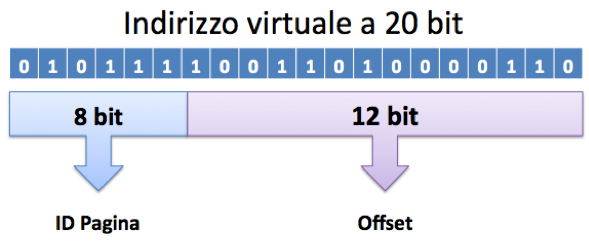
Una simile suddivisione consente ad ogni processo di allocare un massimo di 256 pagine virtuali (28), la cui dimensione è pari a 4,096 byte (212): ovviamente il numero di pagine virtuali disponibili per un processo è indipendente dal numero di frame disponibili. Qualora il rapporto tra i frame disponibili ed il numero massimo di processi concorrenti risulti vantaggioso, il programma attiverà automaticamente la paginazione anticipata: l’MMU, infatti, non si limiterà a caricare in memoria la pagina mancante, causa del fault, ma anche un ristretto numero di pagine adiacenti. In pratica il simulatore cerca di prevedere quali pagine saranno richieste in virtù della località dei dati e le carica prima di quando queste vengano effettivamente richieste.
La suddetta funzionalità è da considerarsi puramente dimostrativa ed embrionale.
Di seguito vengono riassunte le scelte progettuali che caratterizzano il simulatore.
| Ambito | Proprietà | Valore |
|---|---|---|
| Hardware | Dimensione indirizzo | 20 bit |
| Dimensione RAM | 1,048,576 byte | |
| Dimensione frame | 4,096 | |
| Memoria virtuale | Tipo | paginata |
| Politica di rimpiazzo | enhanced second chance | |
| Dimensione pagina | 4,096 | |
| Page table | sempre in memoria | |
| Max pagine/processo | 256 | |
| Dispositivo I/O | Tmin | 1 |
| Tmax | 100 | |
| Processo | Probabilità accesso | 80% |
| Località temporale | 30% | |
| Località spaziale | Loop su un vettore |
Descrizione moduli
Di seguito verranno descritti, con maggiore dettaglio, gli aspetti implementativi dei singoli moduli: l’MMU, il dispositivo di I/O ed il processo.
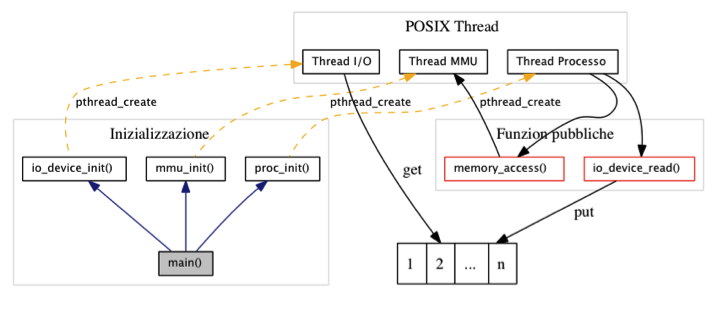
Ogni singolo modulo del simulatore viene inizializzato direttamente dal main() attraverso le rispettive funzioni e sulla base dei parametri specificati da riga di comando. Terminata questa fase, inizierà l’interazione tra i singoli thread.
Memory Management Unit (MMU)
Il thread che emula l’MMU è il primo ad essere istanziato dal simulatore, direttamente all’interno del main: questo si occupa della traduzione di un indirizzo virtuale, generato da un processo, in un equivalente indirizzo fisico di memoria.
La funzione mmu_init è incaricata di configurare l’ambiente del simulatore nonché di partizionare la memoria fisica in frame. Ad ogni frame verranno associate le seguenti informazioni:
- id: tale valore identifica univocamente un frame;
- physical_addr: questa variabile conterrà l’indirizzo di memoria fisica di partenza del frame; durante il ciclo di vita del simulatore, la lista dei frame non sarà ordinata per id: questo è il valore di base cui sommare l’offset dell’indirizzo virtuale;
- valid: il bit verrà posto ad uno (1) quando il frame è utilizzato;
Ad ogni frame vengono inoltre associate due ulteriori campi, pid e page_id: sebbene non siano necessari al funzionamento del simulatore, hanno il solo scopo di rendere più semplice il debug, nonché offrono la possibilità di mantenere un’associazione frame –> processo –> pagina.

L’MMU fa uso di due liste semplici: la prima, free_frames, per tenere traccia dei frame liberi (ovvero non associati ad alcuna pagina) ed used_frames per i frame utilizzati. Terminata l’inizializzazione della memoria, tutti i frame saranno presenti nella lista free_frames, condizione dettata dal demand paging. Un’ulteriore lista, active_pages, conterrà solo le pagine presenti in memoria.
La funzione thread_mmu viene eseguita come thread e simula l’MMU: l’interazione tra questo thread ed i processi è resa possibile dalla funzione memory_read, invocata direttamente dai processi che tentano un accesso alla memoria. Quest’ultima si occuperà di inserire in una struttura temporanea i dati relativi al processo chiamante, nonché l’indirizzo virtuale richiesto e segnalerà alla MMU la presenza di una richiesta; l’MMU, nel vagliare la richiesta, sceglierà quale frame associare alla pagina equivalente ed, al termine, restituirà l’indirizzo di memoria fisico.
Di seguito verrà illustrato lo schema a blocchi del funzionamento della MMU.

L’algoritmo enhanced second chance viene applicato solo quando la pagina richiesta non è presente in memoria ed, al contempo, tutti i frame risultano occupati. Ha quindi inizio una ricerca della pagina candidata alla rimozione: i due bit precedentemente descritti, reference e dirty, tengono traccia dell’uso e della modifica delle pagine.
L’algoritmo prevede che l’elenco delle pagine utilizzate sia rappresentato da una lista circolare, mentre è stata usata una lista doppiamente concatenata che, nel caso peggiore, viene visitata per intero.
Processo
La funzione thread_proc, eseguita come thread, si occupa di simulare un processo utente.
La rappresentazione in memoria del singolo processo, nonché delle caratteristiche che lo contraddistinguono, è affidata alla struttura proc. Avendo come riferimento un sistema operativo reale, al proprio interno, il simulatore gestisce una lista di tutti i processi attivi, detta process table: ogni voce in questa tabella è di tipo proc e contiene le seguenti informazioni:
- pid: identificativo univoco del processo;
- tid: identificativo univoco del thread che simula il processo;
- page_count: numero di pagine virtuali allocate dal processo;
- page_table: tabella delle pagine del processo; questa informazione non deve essere accessibile al processo;
- percentile: probabilità del processo di effettuare un accesso alla memoria piuttosto che al dispositivo di I/O;
- io_cond/io_lock: condizione e relativo mutex nel quale il thread resta in attesa di completamento di una richiesta di I/O;
- log_file: file di log del processo;
- proc_stats: struttura per contenere le statistiche d’accesso del processo.
Nei sistemi reali, un processo ha visibilità solo di alcune informazioni contenute nella process table o relative al sistema ospite: per esempio, un processo potrà sapere qual è il proprio pid o la dimensione della memoria virtuale, ma non potrà tuttavia accedere alla lista delle pagine o dei frame, informazioni ad unico appannaggio del sistema operativo. Seguendo le implementazioni dei più comuni sistemi nix si è dunque scelto di non far gestire alla mmu la tabella delle pagine virtuali del processo, garantendo opportunamente la protezione dello spazio d’indirizzamento: l’mmu farà piuttosto uso di una propria struttura dati per gestire l’associazione delle pagine ai frame. Questa scelta trova ulteriore giustificazione nel fatto che ogni processo può allocare una quantità variabile di memoria e l’mmu, che viene inizializzata prima della process table*, non può conoscere a priori tale quantità.
Poiché il simulatore non è stato implementato con un linguaggio orientato ad oggetti quale Java o C++, le API di accesso alla memoria ed al dispositivo di I/O devono contenere necessariamente l’identificativo del richiedente, nello specifico il pid.
La funzione proc_init ha il compito di creare n istanze del thread processo, per ognuno dei quali associa un numero casuale di pagine virtuali.
Il numero casuale di pagine virtuali è compreso tra 1 e 256, in modo tale che tutti i processi abbiano almeno una pagina associata e comunque non superiore al limite massimo di 256. È tuttavia possibile massimizzare tale valore per tutti i processi usando il parametro –M.
La funzione thread_proc, si occupa di scegliere se effettuare un accesso alla memoria o al dispositivo di I/O, scegliendo tra le due operazioni con una probabilità impostata dall’utente: quando la funzione memory_access, utilizzata per accedere alla memoria, restituirà il valore -1, i processi termineranno la propria esecuzione.
L’accesso in memoria osserva il principio di località, secondo cui:
- se accedo ad un dato, probabilmente accederò anche a quelli vicini in un tempo non lontano (località spaziale);
- se accedo ad un dato è probabile che debba accedervi nuovamente in breve tempo (località temporale).

La realizzazione della località spaziale viene offerta dalla funzione simulate_loop che si occupa di simulare un accesso ad un vettore di n elementi: poiché in C gli elementi di un vettore occupano indirizzi di memoria contigui, simulare un accesso ad ognuno di essi coincide ad una località spaziale.
Quando il processo effettua invece un accesso pseudo casuale alla memoria, subentra la località temporale, ovvero la possibilità di accedere ad un dato recentemente utilizzato. In quest’ottica, il processo avrà il 30% di probabilità di accedere ad un indirizzo di memoria usato in precedenza.
Il parametro “–L” permette di variare la percentuale di località temporale, di default pari a 30%; ponendo uguale a zero tale valore, si elimina l’effetto di località.
L’operazione di lettura merita ulteriori considerazioni:
- nel caso di accesso alla memoria, l’indirizzo virtuale è generato casualmente, ma è sempre compreso nello spazio d’indirizzamento virtuale del processo: qualora l’indirizzo fuoriuscisse da tale spazio, il simulatore avrebbe il compito di generare un fault e terminare il processo;
- per una migliore simulazione dell’algoritmo scelto, che prevede l’uso del bit dirty, è stata implementata l’operazione di scrittura in una zona di memoria: la funzione che realizza tale operazione è sempre memory_access ma con il parametro rw posto ad uno; non sarà tuttavia presente un parametro utile a rappresentare l’informazione da scrivere in memoria, in quanto esula lo scopo della presente analisi;
- per entrambe le tipologie di accesso, alla memoria od al dispositivo di I/O, il processo non ha visibilità diretta dei rispettivi thread: la possibilità di effettuare una richiesta viene offerta dall’uso di due funzioni pubbliche che svolgono il ruolo di intermediario.
Sussiste una sottile differenza tra i due tipi di accesso che un processo utente può effettuare: l’MMU rappresenta un oggetto condiviso tra più processi e può assolvere una richiesta per volta; se n processi tentassero l’accesso alla memoria, soltanto uno riuscirà nell’intento mentre gli altri “n-1” processi restano in attesa (mutua esclusione).
Di contro, l’accesso al dispositivo di I/O prevede che effettuare una richiesta d’accesso non sia bloccante, per cui se n processi tentassero l’accesso al dispositivo, tutti quanti riuscirebbero ad inserire la propria richiesta in coda: l’attesa avviene immediatamente dopo, non bloccando quindi gli altri attori della contesa, ma solo il processo che attende il risultato.
Di seguito viene illustrato il diagramma a blocchi del funzionamento del thread processo.

La prima condizione, uscita, viene soddisfatta quando la MMU ha effettuato il numero richiesto di accessi.
Dispositivo di I/O
Il dispositivo di I/O viene emulato dalla funzione thread_io_device, anch’essa eseguita come thread. Questo viene inizializzato ed istanziato immediatamente dopo aver creato il sottostrato di memoria virtuale.
Il funzionamento del dispositivo di I/O, a differenza della MMU, si basa su una lista di tipo FIFO: i processi che effettuano una richiesta a tale dispositivo vengono inseriti in coda e serviti in modo sequenziale. La richiesta è di tipo bloccante: un processo, in attesa che la richiesta venga soddisfatta, non può effettuare altre operazioni.
La funzione io_device_read rappresenta il metodo pubblico per inserire una richiesta in coda, al pari di memory_access per le lettura in memoria.
La coda di richieste di I/O costituisce una risorsa condivisa tra il thread (lettore) e la funzione io_device_read (scrittore) ed, in tal senso, l’accesso alla FIFO va gestito all’interno di una sezione critica: il mutex fifo_lock viene utilizzato dalle due entità al fine di mantenere coerente lo stato delle richieste.
Il thread terminerà la propria esecuzione su richiesta dell’MMU, quando questa avrà espletato il numero di richieste previsto.
Di seguito viene illustrato il diagramma a blocchi del dispositivo.

Come da specifica, il dispositivo viene configurato con due parametri, Tmin e Tmax, rispettivamente il tempo minimo e massimo perché una richiesta di lettura venga effettuata; il thread, una volta esaminata la richiesta, si occuperà di generare un numero casuale compreso in tale intervallo ed infine segnalerà al processo l’avvenuta operazione: il processo sarà nuovamente libero di effettuare altre operazioni con le modalità precedentemente descritte.
Prima fase: analisi dei parametri
Il programma inizierà la propria esecuzione analizzando i parametri specificati su riga di comando; sebbene questi non siano necessari per il funzionamento del simulatore, è disponibile un insieme di parametri per modificare alcuni comportamenti predefiniti dell’applicativo.
Di seguito vengono riassunti i possibili parametri:
| Breve | Lungo | Descrizione |
|---|---|---|
| -v | –version | Stampa la versione del programma ed esce |
| -d | –debug | Aumenta il livello di debug dell’output (disattivato per default) |
| -a | –anticipatory-paging | Disabilita la paginazione anticipata |
| -h | –help | Stampa la sinossi del programma ed esce |
| -l *lista* | –probabilities=*lista* | Specifica la probabilità d’accesso alla memoria per i processi |
| -L *num* | –locality=*num* | Specifica la località temporale (default: *30%*) |
| -M | –all-memory | Forza i processi ad allocare il massimo della memoria (default: *no*) |
| -m *num* | –max-read=*num* | Imposta il numero massimo di accessi alla memoria (default: *50*) |
| -p *num* | –max-processes=*num* | Imposta il numero massimo di processi concorrenti (default *5*) |
| -P *num* | –probability=*num* | Imposta la probabilità con cui un processo effettua un accesso alla memoria (default: *80%*) |
| -r *lista* | –reference=*lista* | Imposta la *reference string* per determinare gli accessi |
| -R *num* | –ram-size=*num* | Imposta la dimensione della RAM disponibile (default: *1,048,576*) |
| -s *num* | –frame-size=*num* | Imposta la dimensione della pagina e del frame (default: *4,096*) |
| -t *num* | –Tmin=*num* | Imposta il parametro Tmin del dispositivo di I/O (default: *1*) |
| -T *num* | –Tmax=*num* | Imposta il parametro Tmax del dispositivo di I/O (default: *100*) |
| -w | –write-enabled | Consente ai programmi di accedere alla memoria anche in scrittura (default: *no*) |
Seconda fase: inizializzazione ed esecuzione thread
La corretta analisi dei parametri specificati su riga di comando permette di passare alla inizializzazione delle singole strutture dati ed all’esecuzione dei thread finora descritti.
La prima entità istanziata è appunto l’MMU, seguita successivamente dalla creazione del thread per il dispositivo di I/O ed in ultimo dai thread che simulano i processi utente.
Terza fase: stampa dei risultati
La terza fase ha inizio quando i processi utente hanno effettuato il numero massimo di accessi alla memoria: questa condizione determina la fine di tutti i thread istanziati, siano essi utente, MMU o del dispositivo di I/O.
Una corretta conclusione prevede quindi di effettuare una pthread_join di tutti quanti i thread e la relativa deallocazione delle strutture dati fino a quel momento utilizzate.
Al termine di questa operazione, il simulatore si dovrà preoccupare di stampare a video le statistiche richieste. Oltre le suddette statistiche, saranno inoltre disponibili, nella directory di lavoro, i file di log di ogni singolo processo, all’interno dei quali si potrà trovare la lista delle operazioni effettuate dai processi utente.
Scarica l’intero progetto qui.